windows - PDF에서 테이블 추출하기
상황
PDF파일에서 테이블을 추출하기 위해 OCR을 사용하거나, CSV로 변환하는 등 많은 방법을 사용해 보았다.
하지만 테이블을 온전한 형태로 추출하는 것은 거의 불가능했고, 각각의 방법마다 뭔가 하나 빠진듯한 결과물이 나왔다.
- PDF의 테이블은 테이블 형태의 데이터가 아니라 텍스트 + 이미지(라인)이기 때문에 벌어지는 현상으로 추정된다.
#1 python - camelot
현재까지 사용해본 방법중에서는 python의 camelot 패키지가 가장 우수한 결과를 보여준다. PDF 파일을 선택하면, 테이블이 있는 페이지에 대하여, 각 시트별로 테이블을 작성해준다.
sample,py
import camelot
import pandas as pd
from tkinter import Tk
from tkinter.filedialog import askopenfilename, asksaveasfilename
# Hide the main Tkinter window
root = Tk()
root.withdraw()
# 1. Select a PDF file
pdf_file = askopenfilename(
title="Select PDF File",
filetypes=[("PDF files", "*.pdf")]
)
if not pdf_file:
print("No PDF file selected.")
exit()
# 2. Extract tables from the PDF using Camelot
# 'lattice': for tables with lines, 'stream': for tables without lines
tables = camelot.read_pdf(pdf_file, pages='all', flavor='lattice')
if tables.n == 0:
print("No tables found in the PDF.")
exit()
print(f"Number of tables found: {tables.n}")
# 3. Select the location to save the Excel file
excel_file = asksaveasfilename(
title="Save as Excel",
defaultextension=".xlsx",
filetypes=[("Excel files", "*.xlsx")]
)
if not excel_file:
print("No Excel file selected.")
exit()
# 4. Save all extracted tables into an Excel file, each table in a separate sheet
with pd.ExcelWriter(excel_file, engine='openpyxl') as writer:
for i, table in enumerate(tables):
sheet_name = f"Table_{i+1}" # Sheet name for each table
table.df.to_excel(writer, index=False, sheet_name=sheet_name)
print(f"Excel file saved successfully: {excel_file}")
#2 excel - vba
엑셀 본연의 기능만으로 돌파를 해본다.
아래와 같은 표가 있다고 했을 때, 1번 값부터 복사를 하면, 엑셀에 바로 붙이면, 다음과 같이 붙는다.
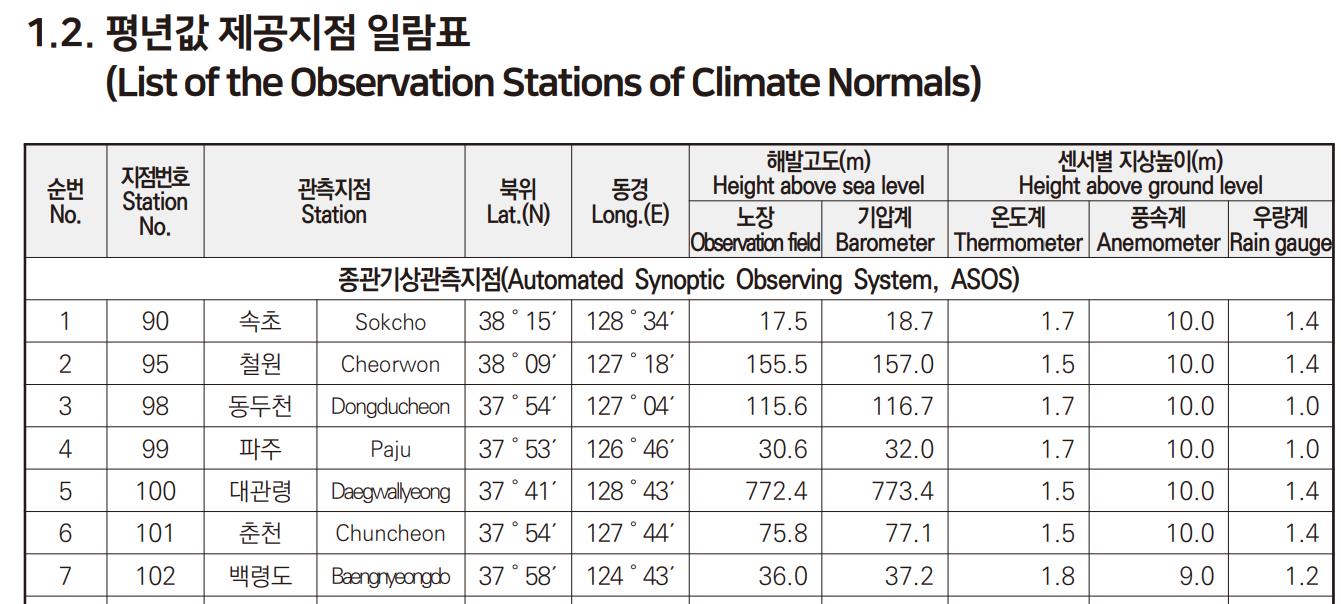
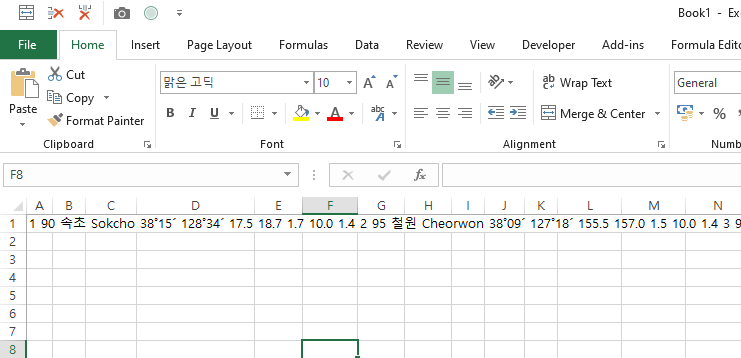
위의 원본 테이블을 유심히 보면 알 수 있지만, 셀 안에 공백이 하나도 없다. 그러므로 사실 해당 테이블은 그렇게 까다로운 테이블이 아니다. 여백이 발생하는 경우, 컬럼을 구분해주면 되기 때문이다.
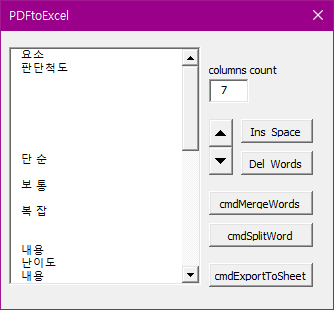
간단한 VBA 코드만으로 이를 파싱하는 코드를 바로 짤 수 있다. 아래와 같이 간단한, userform을 만들었다.
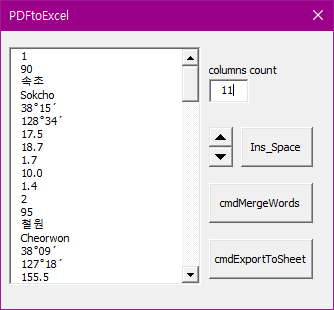
컬럼을 몇개를 사용할지만, 지정해주면 다른 작업이 필요가 없다. ExportToSheet 버튼 한번이면 된다.
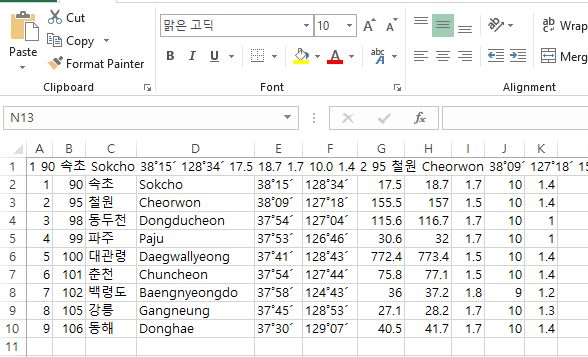
문제는 테이블 값들 안에 여백이 있는 경우이다. 이때는 같은 셀 안에 있어야할 값들을 머징해주는 과정이 필요하다. 예를들어 아래와 같은 테이블이 있다고 하자.

아래와 같이 userform에서 같은 셀안에 있어야 할 값을 붙여주고, 순서가 이상하다면 순서도 맞춰줘야 한다.
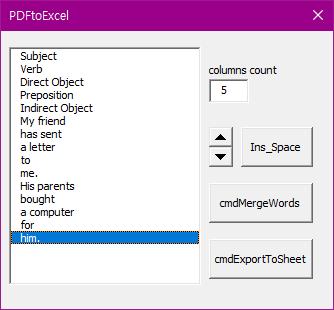
결과는 다음과 같다.
마지막으로 맨 위에 사용했던 예제의 header처럼, 셀 병합이 되어있는 경우이다. 알겠지만, 병합이 된 셀의 경우, 값이 없을 뿐 자리는 차지를 해야한다. 따라서, 빈 문자로 자리를 잡아줘야 한다.
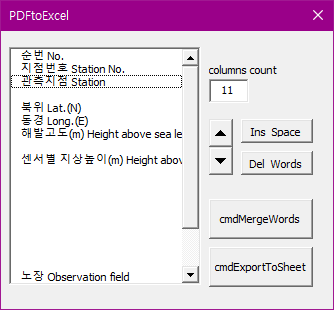
아래 header는 총 11개이고, 두번째 줄은 7번째 부터 시작한다.

아래와 같이 비어있는 셀을 고려하여 작성을 한다.
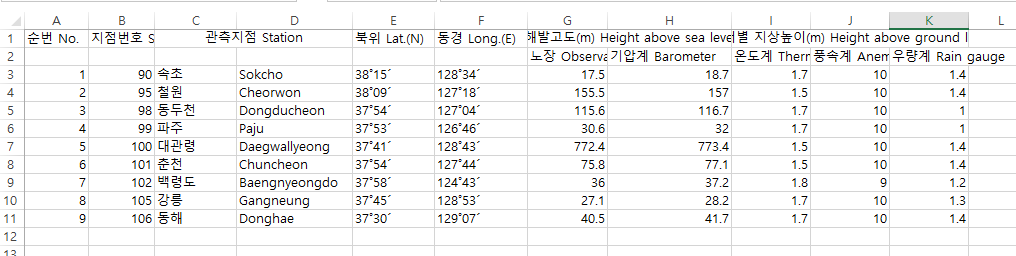
엑셀의 결과는 다음과 같다.

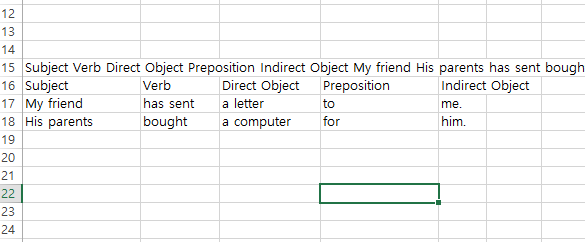
위에서 했던 데이터와 합쳐서 사용한다면 다음과 같다.
다른 예시를 한 번 보자. 위와 마찬가지로, 헤더가 복잡하게 되어있는 테이블이다.
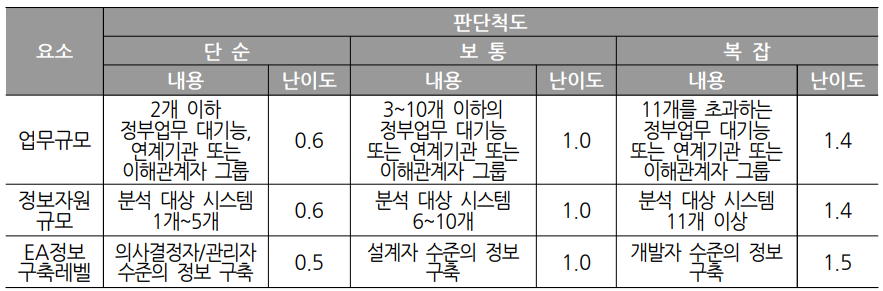
아래와 같이 분리를 해주면 된다.
그야말로 복잡하다.
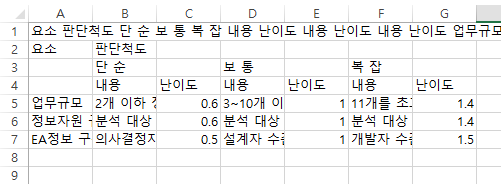
PDF 안에 있는 테이블에 대한 이해는 좀 필요할 듯하다. 예를 들어 아래와 같은 표라면, 구지, 이 방법 보다는, 그냥 copy-paste 하는 것이 더 빠를 수 있다는 것이다.
구지 적용하자면 아래와 같이 가능은 하지만, 꽤나 오래 걸린다. 이런 경우 그냥 메모장을 이용하는 방법이 낫겠다.

#3 excel - from web
PDF파일을 크롬브라우저에서 열면 주소창에 로컬 저장소의 주소가 찍히는데,
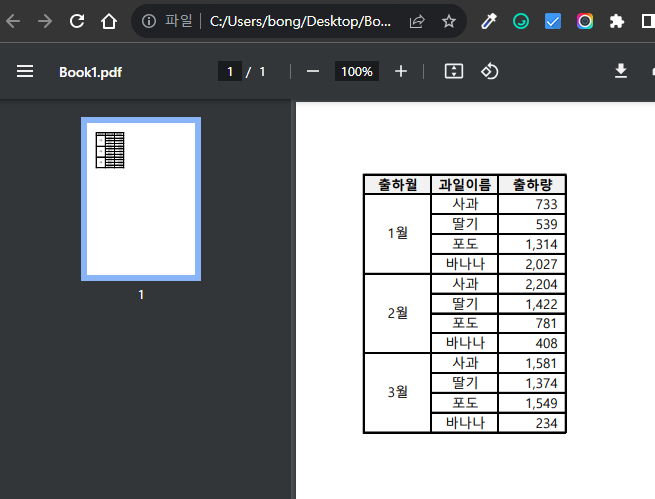
엑셀의 데이터 탭에서, From Web (한글로 뭐였는지 모르겠다)를 클릭하면,
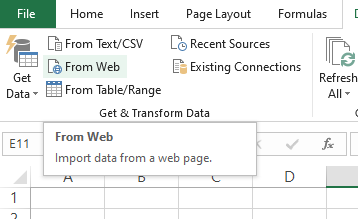
주소를 넣는 창이 뜨는데, 크롬브라우저상의 주소를 기재하여 파워쿼리까지 불러올 수 있다. 메모장에 붙여넣는 수고로움이 덜어진다.
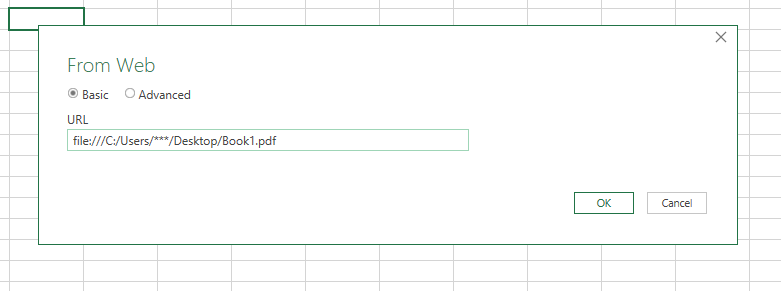
파일명을 더블클릭해주고,
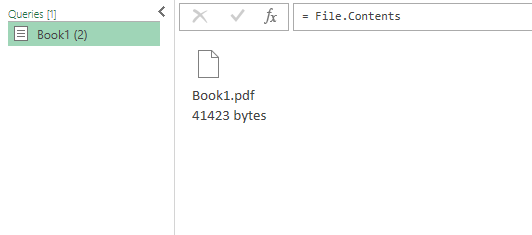
데이터 열에 있는 첫번째 Table을 클릭한다.
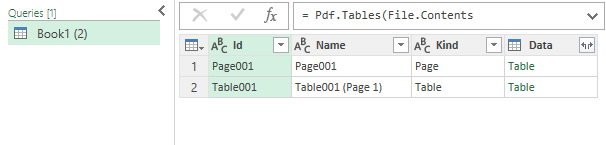
만약 여러 페이지가 있고, 테이블도 여러개가 있는 경우에는, 테이블의 row가 페이지별로 구분되어, 원하는 테이블만 선택할 수 있다.
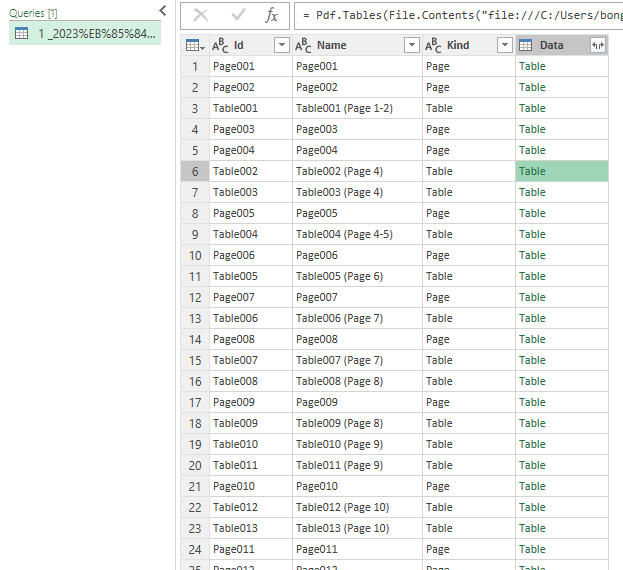
그럼 아래와 같이 테이블을 확인할 수 있다.
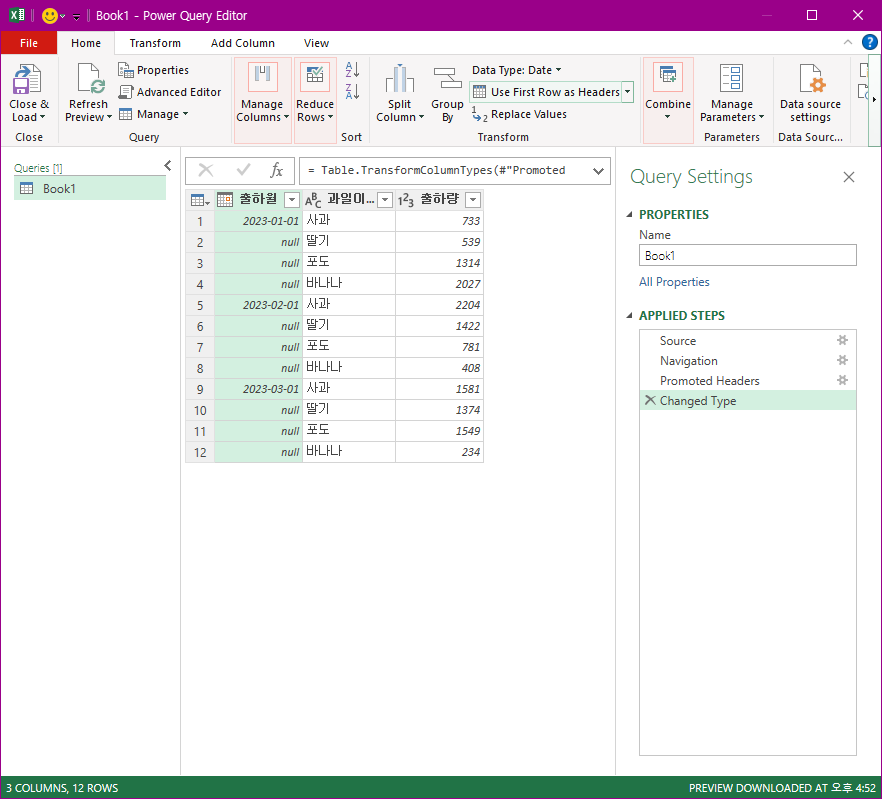
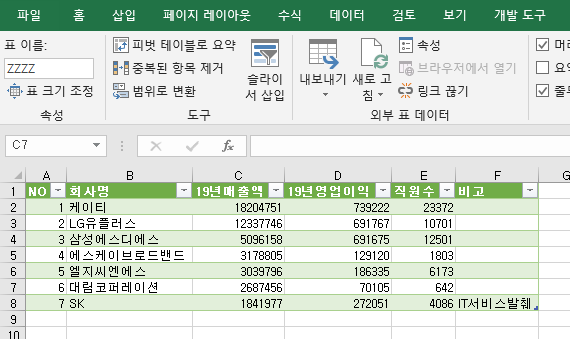
눌러주면, 엑셀에 테이블이 생성된다. 원본 테이블과 거의 차이가 없을을 알 수 있다.
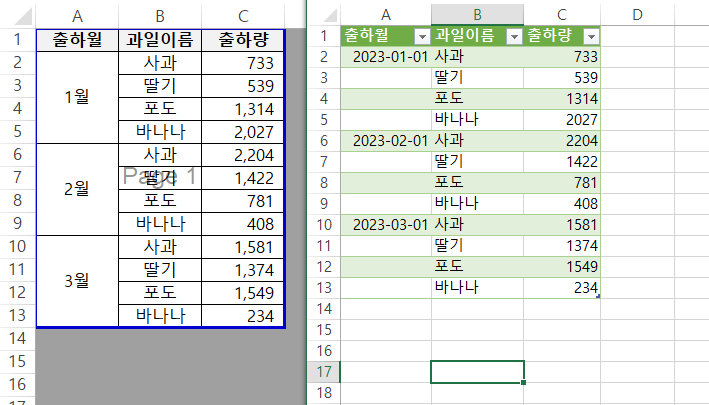
물론, 간단한 테이블만 빠르게 복사할 때는 메모장에 복사하는 방법이 여전히 유효할지 모른다.
#4 excel - OCR
MS365에서는 OCR 기능을 활용해서 이미지를 데이터화 하는 기능이 있다. 역시, MS의 AI는 갑자기 하늘에서 떨어진게 아니다.
회사에서 2019 버전을 사용하는 관계로, 해당 기능은 없다. 그래서 아직 몰랐던 것 같다. 그러나, 온라인 엑셀에 최신 기능이 어느정도 반영되어있을 것이라 생각해서 찾아본 결과 역시, 기능이 있었다.
아래 주소로 온라인엑셀에 접속하자, 당연히 MS계정은 있어야하겠다.
https://www.office.com/launch/excel
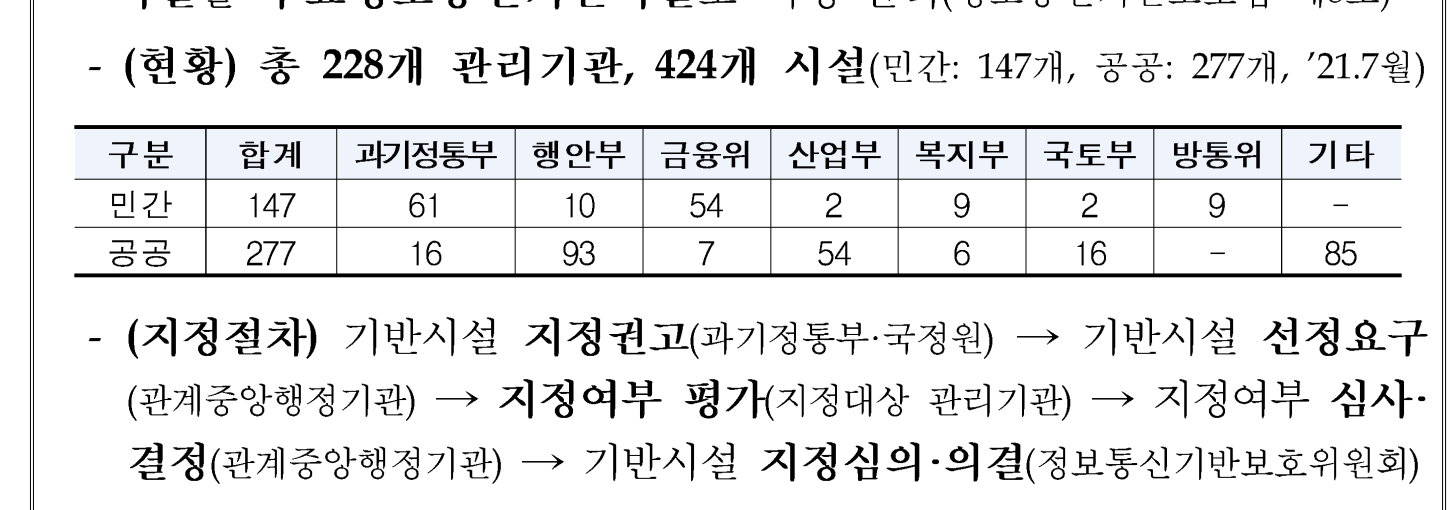
이제 PDF 표를 옮겨 보자. 아래와 같이 PDF 내 표가 있다.
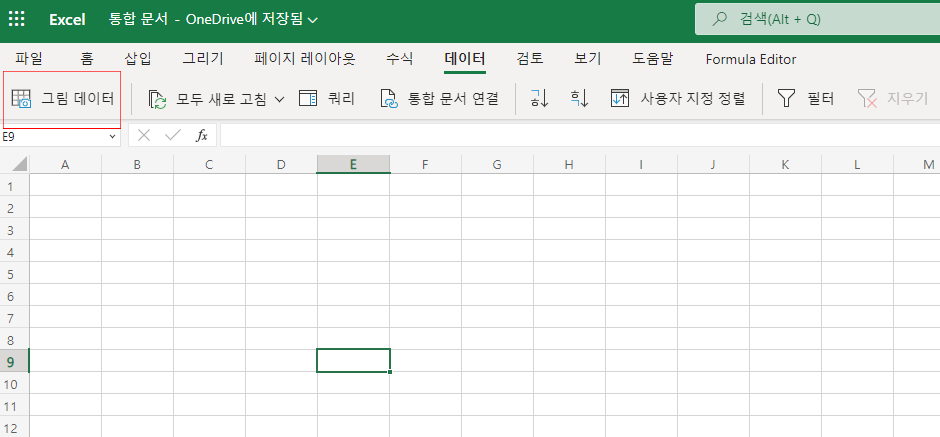
스크린 샷을 통해 해당 표를 이미지로 만들어 준다. OCR(Optical Character Recognition)을 활용하므로 화질은 깨끗한 것이 좋겠다.
온라인 엑셀에 들어와서, 데이터 탭의 맨 왼쪽, 그림데이터를 클릭하면, 그림 선택 탐색기가 뜬다. 이미지를 선택하면, 작업의 90%는 끝난다.
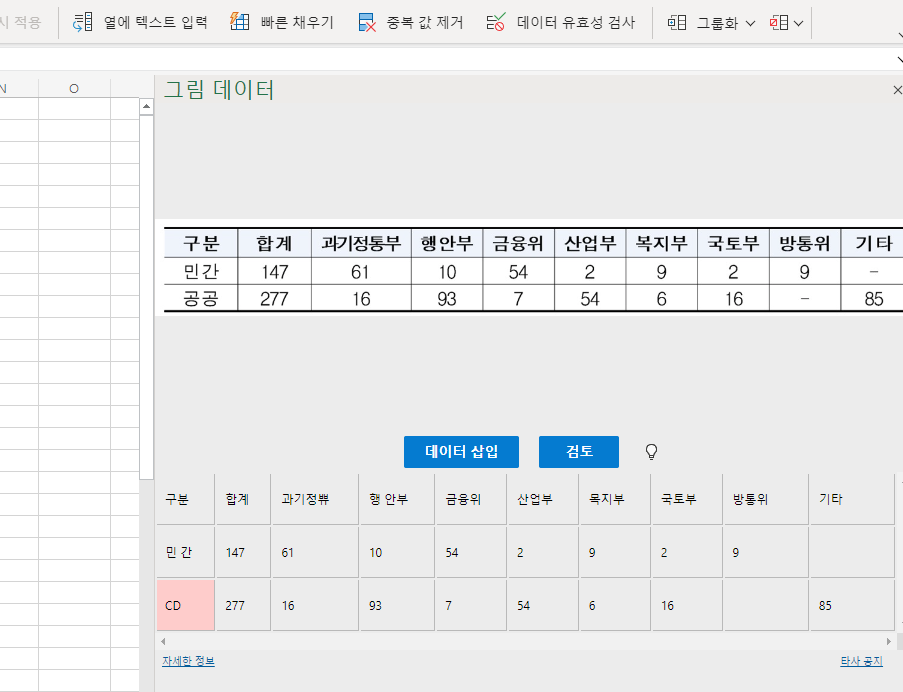
엑셀의 우측에 해석한 결과가 뜨고, 제대로 입력이 되었는지 확인하고, 수정할 수 있는 창이 뜬다.
한글은 다소 깨지는 듯하고, 숫자는 거의 결과가 맞는 것 같다. 중요한 건 숫자니까…
해당 창에서 텍스트를 수정해도 되고, 불러와서 엑셀에서 수정을 해도 된다.

자 아래와 같이 데이터를 삽입해줬다. 로컬 엑셀로 복사를 해주고 작업을 진행하면 된다.
위에 기술했 듯, ‘과기정쀼’ 나 ‘행 안부’ 같이 띄어쓰기 혹은 전혀 이상한 말이 들어가 있다면 수정해주면 된다.

이미지 처리되어, 텍스트가 긁히지 않는 PDF에서 잘 써먹을 수 있을것 같다.
여담이지만, ai 서비스들도 많이 있으니, 시간될 때, 여러가지를 시도해 보는 것도 좋겠다.
#5 notepad, csv
아래와 같은 표가 있다고 하면,
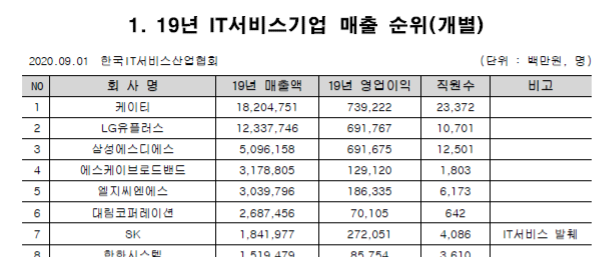
그냥 카피-페이스트를 하면, 이런식으로 붙는다.

자세히 보면, 컬럼이 공백으로 분리되어 있음을 알 수있다. 방법은 PDF 표복사 → 메모장 붙여넣기 → CSV파일 저장하기 → 엑셀에서 CSV불러오기 순서로 진행하면 된다.
표를 복사해서 메모장에 넣어준다. 아래 회사명처럼 공백이 이상한곳에 있는 경우, 임의로 붙여줘야한다. 인공지능 따위는 없다.

CSV파일로 저장한다. 여기서 한글 인코딩 방식을 잘 봐둔다. UTF-8이다.
엑셀 데이터 탭에서, 텍스트/CSV 메뉴를 눌러주자.
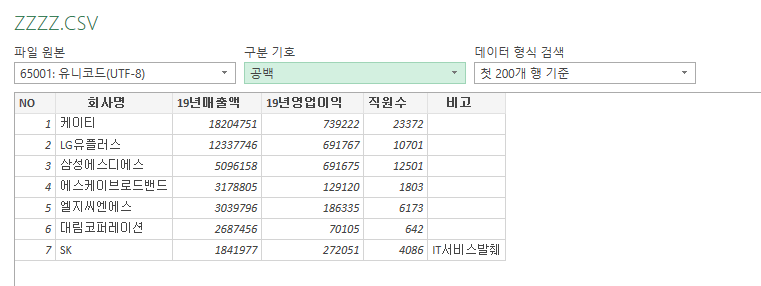
엑셀 버전마다 보이는 창이 다를 수 있다. 아래 창은 2019버전이다. 인코딩방식(파일 원본)을 UTF-8로, 구분기호를 공백으로 해준다.
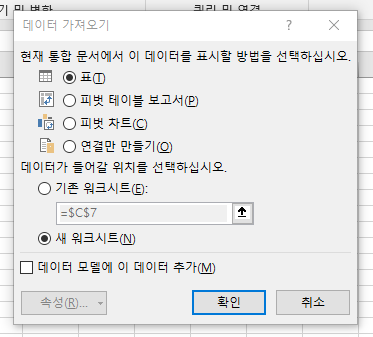
다 된거라 할수 있다. 로드 버튼을 눌러 불러오거나 데이터변환 버튼을 통해 파워쿼리를 실행할 수 있다. 문제가 없다면 로드 버튼을 누르자. 로드 버튼의 옵션을 통해 불러올 방식을 정할 수 있다.
기본 값은 데이터표이다.
데이터 표가 완성됐다.
끝.